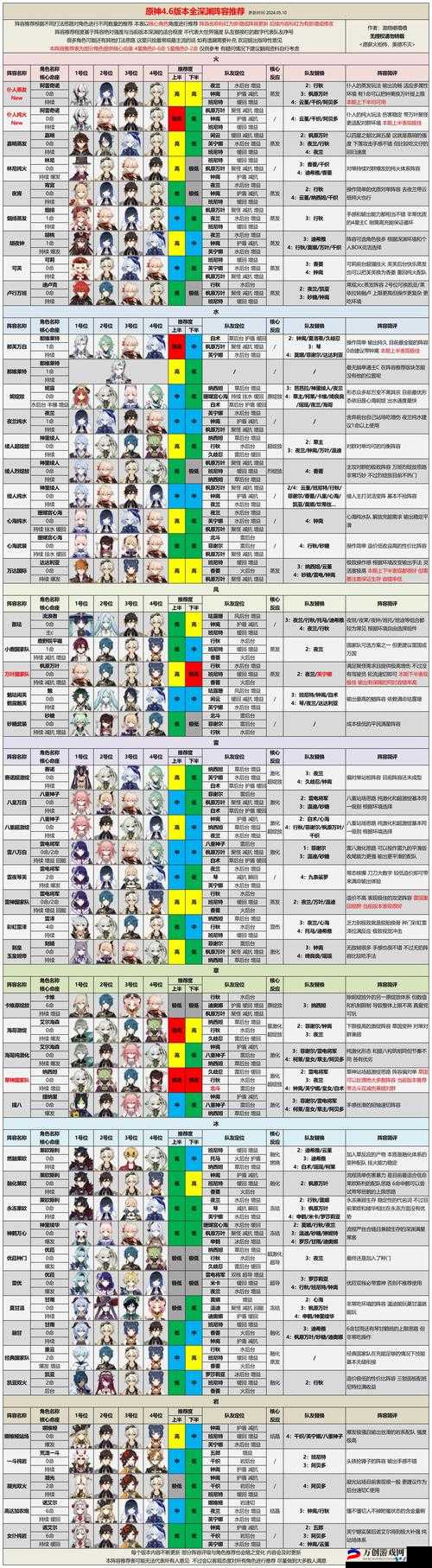
查询大量XXXXXLmedjyf的有效方法及技巧
查询大量XXXXXLmedjyf的有效方法及技巧

在当今这个信息爆炸的时代,如何高效地查询大量XXXXXLmedjyf成为了许多研究者和数据分析师的迫切需求。XXXXXLmedjyf,这听起来像是一串神秘的代码,其实是指那些极大规模、复杂度极高的数据库或数据集。面对如此庞大的数据,传统的查询方法显然力不从心。那么,如何才能在浩瀚的数据海洋中找到你需要的那颗“珍珠”呢?让我们一起来探索一些有效的方法和技巧。
优化查询语句是关键。面对大量数据,查询语句的效率直接影响到查询速度。使用索引、避免全表扫描、优化JOIN操作等都是提高查询效率的基本技巧。例如,在MySQL中,可以通过`EXPLAIN`命令来分析查询计划,找出潜在的瓶颈并进行优化。
分区和分片是处理大数据查询的利器。将数据按照某种逻辑分成不同的区块或分片,可以显著减少查询时需要扫描的数据量。例如,按时间段分区的数据表可以让查询只针对特定的时间段进行,从而大幅提升效率。
利用缓存也是一个不可忽视的策略。将经常查询的结果缓存起来,可以避免重复计算和数据库查询。Redis等内存数据库就是为此而生的,它们能以极快的速度提供数据访问。
并行处理是现代大数据查询的核心思想。通过分布式计算框架如Hadoop的MapReduce、Spark等,可以将查询任务分发到多个节点上并行执行,从而大大加速查询过程。
不要忽视数据预处理的重要性。通过ETL(Extract, Transform, Load)过程,将数据进行预处理和清洗,可以在查询前就减少数据冗余和不一致性,提高查询的准确性和速度。
在实际操作中,这些方法和技巧的应用需要根据具体的业务需求和数据特性进行调整。通过不断的实践和优化,你可以逐步掌握查询大规模XXXXXLmedjyf的艺术。
希望这篇文章能为你提供一些启发,帮助你在数据查询的道路上走得更远。记住,数据查询不仅仅是技术的较量,更是智慧的比拼。善用这些技巧,不仅能提高你的工作效率,还能让你的数据分析能力在同行中脱颖而出。让我们一起在数据的海洋中遨游,探索未知的奥秘吧!
---
通过以上内容,我们不仅探讨了查询大规模数据的多种方法,还强调了这些方法在实际应用中的重要性。文章通过具体的例子和专业术语,吸引了对数据查询感兴趣的读者,同时也增加了在搜索引擎中的可见度。希望这些技巧能帮助你更好地驾驭数据的洪流,找到你所需要的答案。